C++ 学习笔记
std::move 移动
对于 指针和内置类型(不存在移动构造或者赋值), std::move 对其不起作用
1 |
|
以上代码应该 a b 成员的地址应该是一样的才对, 然而发现 输出结果为
|| 有参构造的移动版本
|| char[ 140730472567184 ]
|| int[ 94096362569392 ]
|| 默认构造
|| 移动赋值
|| char[ 140730472567248 ]
|| int[ 94096362569392 ]
这是由于 samll string optimization 导致的
small string optimization : gcc 当字符串长度不大于15的时候,不会进行动态内存分配,而是直接存储在std::string的结构体内
Lambda捕获成员变量
实际上捕获 this 指针。无论是传值捕获还是引用捕获,this的捕获方式永远是按值传递。
时间复杂度
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
set、multiset、map、multimap
特点:底层实现是红黑树,键值有序,set 和 map 键不可重复,而 multiset 和 multimap 可重复;
复杂度:插入、删除、查找都为O(logN);unordered_set,unordered_map,unordered_multiset,unordered_multimap
特点:底层实现是哈希表,键值无序,unordered_set 和 unordered_map 键不可重复,而另外两个可以重复;
复杂度:插入、删除、查找平均为O(1),最坏为O(N),空间换时间;vector
特点:底层实现是数组,动态成倍扩容;
复杂度:
插入:push_back(),O(1);insert(),O(N)
删除:pop_back(),O(1);erase(),O(N)
查找:O(1)list
特点:底层实现双向链表;
复杂度:
插入:push_front(),O(1);push_back(),O(1);insert(),O(1)
删除:pop_front(),O(1);pop_back(),O(1);erase(),O(1)
查找:O(N)deque 双端队列
特点:底层是分段连续的线性空间,它是一种具有队列和栈的性质的数据结构,其插入和删除操作限定在两端进行;
复杂度:
插入:push_front(),O(1);push_back(),O(1);insert(),O(N)
删除:pop_front(),O(1);pop_back(),O(1);erase(),O(N)
查找:O(1)stack 栈
特点:底层实现一般用 list 或 deque,封闭头部即可,数据先进后出,不支持随机访问;
复杂度:
插入:push(),O(1)
删除:pop(),O(1)
查找(栈顶):top(),O(1)queue 队列
特点:底层实现一般用 list 或 deque,数据先进先出,不支持随机访问;
复杂度:
插入:push(),O(1)
删除:pop(),O(1)
查找(队列头):front(),O(1)priority_queue 优先队列
特点:底层用堆实现,队列中各个元素被赋予优先级;
复杂度:
插入:push(),O(logN)
删除:pop(),O(logN)
查找(取堆顶):top(),O(1)
版权声明:本文为CSDN博主「西瓜味儿的小志」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Destiny_shine/article/details/104291888
指针初始值
g++ 内置指针初始值默认为空
clang 内置指针初始值随机
quickfix 窗口 和 内置terminal
quickfix: 可以跳转错误, 快捷键打开支持, 高度设置支持
terminal: 颜色支持, cin 支持,
所以还是两个都用吧。。。
暂时找不到结合这两个的方法
模板重载 判断变量类型 以及拓展
https://www.itcodar.com/c-plus-1/determine-if-type-is-a-pointer-in-a-template-function.html
测试嵌入 html 代码 (虽然可以 但是不知道为什么 html 文件出bug了 而且也没啥用, 不如不嵌入。。)
1 | <iframe src="/home/qinjin/Blog/source/html/9.hpp.html" height="500px" width="100%" scrolling="auto" frameborder="1" style="box-shadow: 0px 0px 20px -10px #888;"> |
版权声明:本文为CSDN博主「真实的hello world」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33384402/article/details/107240192
使用 二进制文件读写数据的好处
使用二进制文件的好处
为什么要使用二进制文件。原因大概有三个:
第一是二进制文件比较节约空间,这两者储存字符型数据时并没有差别。但是在储存数字,特别是实型数字时,二进制更节省空间,比如储存 Real4 的数据:3.1415927,文本文件需要 9 个字节,分别储存:3 . 1 4 1 5 9 2 7 这 9 个 ASCII 值,而二进制文件只需要 4 个字节(DB 0F 49 40)
第二个原因是,内存中参加计算的数据都是用二进制无格式储存起来的,因此,使用二进制储存到文件就更快捷。如果储存为文本文件,则需要一个转换的过程。在数据量很大的时候,两者就会有明显的速度差别了。
第三,就是一些比较精确的数据,使用二进制储存*不会造成有效位的丢失。
也就是存储快, 占空间小, 精确.
版权声明:本文为CSDN博主「Kehl」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Oliverkehl/article/details/20129063
ddd 以及 xterm 配置
https://www.cnblogs.com/cpointer/p/4896050.html
http://blog.lujun9972.win/blog/2016/11/16/xterm%E4%BD%BF%E7%94%A8%E7%AE%80%E4%BB%8B/index.html
intel one API
安装完后设置环境变量 在 .bashrc 添加
1 | source ~/intel/oneapi/setvars.sh > /dev/null |
在cmake 中链接 MKL 参见intel one API 官网
1 | target_link_libraries(${PROJECT_NAME} -lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5 -lpthread -lm -ldl) |
clock() 函数多线程计时不准确
clock()函数的功能: 这个函数返回从“开启这个程序进程”到“程序中调用C++ clock()函数”时之间的CPU时钟计时单元(clock tick)数当程序单线程或者单核心机器运行时,这种时间的统计方法是正确的。但是如果要执行的代码多个线程并发执行时就会出问题,因为最终end-begin将会是多个核心 总共执行的时钟嘀嗒数,因此造成时间偏大。
版权声明:本文为CSDN博主「dwx2046」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq100440110/article/details/51105613
CMake find_package 原理
find_package原理
首先明确一点,cmake本身不提供任何搜索库的便捷方法,所有搜索库并给变量赋值的操作必须由cmake代码完成,比如下面将要提到的FindXXX.cmake和XXXConfig.cmake。只不过,库的作者通常会提供这两个文件,以方便使用者调用。
find_package采用两种模式搜索库:
Module模式:搜索CMAKE_MODULE_PATH指定路径下的FindXXX.cmake文件,执行该文件从而找到XXX库。其中,具体查找库并给XXX_INCLUDE_DIRS和XXX_LIBRARIES两个变量赋值的操作由FindXXX.cmake模块完成。
Config模式:搜索XXX_DIR指定路径下的XXXConfig.cmake文件,执行该文件从而找到XXX库。其中具体查找库并给XXX_INCLUDE_DIRS和XXX_LIBRARIES两个变量赋值的操作由XXXConfig.cmake模块完成。
两种模式看起来似乎差不多,不过cmake默认采取Module模式,如果Module模式未找到库,才会采取Config模式。如果XXX_DIR路径下找不到XXXConfig.cmake文件,则会找/usr/local/lib/cmake/XXX/中的XXXConfig.cmake文件。总之,Config模式是一个备选策略。通常,库安装时会拷贝一份XXXConfig.cmake到系统目录中,因此在没有显式指定搜索路径时也可以顺利找到。
在我遇到的问题中,由于Caffe安装时没有安装到系统目录,因此无法自动找到CaffeConfig.cmake,我在CMakeLists.txt最前面添加了一句话之后就可以了。
set(XXX_DIR your_package_dir)
作者:金戈大王
链接:https://www.jianshu.com/p/46e9b8a6cb6a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Ubuntu 22.04 更新 gcc 后 clang 无法编译 找不到 iostream clangd 无法自动补全
应该是gcc版本的问题 我现在也没搞懂是为什么,总之 卸载所有版本 gcc 后 重新安装 sudo apt install gcc 就好了…
ifortran 下载
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/fortran-compiler.html#gs.go88dq
配置
只需要 ~~
1 | source setvars.sh |
关于 hpp 重定义
第一种情况是 一个 cpp include 了好几个头文件(头文件中存在定义) 且 这几个头文件之间互相 include 编译时就会出错 解决方法也很简单 在头文件添加 #pragma once 就可以了
第二种情况 多个 cpp include 同一个头文件(头文件中存在定义) 由于编译时这两个cpp是分开编译的 所以不会报错 但是链接时 就会报出重定义的错误 解决方法则是 不在头文件中定义函数和变量 或者 只保留一个 cpp 文件 其他文件都 改为 hpp 。因为 include hpp 的本质就是复制 hpp 的内容 到 cpp 文件, 所以其实编译的就只有一个 cpp 文件(坏处应该是改动一个文件 所有文件都要重新编译 但是代码量很小时 也就无所谓了 优点是这样很方便 大幅度减少调用 project中的cpp文件数与编译次数)
hpp 文件 应用
关于 one defination rule ODR global local weak symbol
https://zhuanlan.zhihu.com/p/554387289
https://zhuanlan.zhihu.com/p/380389282
6转子恩格玛机 C++ 实现
1 |
|
1 |
|
cmake 模板更新
1 | cmake_minimum_required(VERSION 3.0) |
带 QT 的 cmake 模板 更新
1 | cmake_minimum_required(VERSION 3.0) |
Fortran cmake 模板
1 | # CMake 版本 |
vim 内置终端
安装 matplotlib-cpp
1 | git clone https://github.com/lava/matplotlib-cpp.git |
.bashrc 中配置头文件目录
1 | export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/include |
CMakeLists.txt 中配置(否则找不到头文件)
1 | find_package(Python3 COMPONENTS Development NumPy) |
https://blog.csdn.net/qq_43495930/article/details/118380291
C++ 可视化库推荐
https://blog.csdn.net/chyuanrufeng/article/details/102808715
输出结果 段错误
解决:
更换backend 为 GTK3Agg
1 | matplotlibcpp::backend("GTK3Agg"); |
不过 弹出的窗口似乎也无法调节 具体参数了 所以感觉还是有段错误吧 因为也没什么影响
GSL 安装
apt
1 | sudo apt install gsl-dev |
编译安装
1 | ./configure && make && sudo make install |
.bashrc 中配置库的路径
1 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib |
CMakeLists.txt 更新
1 | cmake_minimum_required(VERSION 3.0) |
QT 找不到 qtopengl
在qt的安装目录下 我们可以发现
~/Qt/6.2.3/gcc_64/lib/cmake有很多文件夹夹
Qt6 Qt6QmlDomPrivate
Qt6BuildInternals Qt6QmlImportScanner
Qt6BundledLibpng Qt6QmlLocalStorage
Qt6Concurrent Qt6QmlModels
Qt6Core Qt6QmlTools
Qt6CoreTools Qt6QmlWorkerScript
Qt6DBus Qt6QmlXmlListModel
Qt6DBusTools Qt6Quick
Qt6Designer Qt6QuickControls2
Qt6DesignerComponentsPrivate Qt6QuickControls2Impl
Qt6DeviceDiscoverySupportPrivate Qt6QuickControlsTestUtilsPrivate
Qt6EglFSDeviceIntegrationPrivate Qt6QuickDialogs2
Qt6EglFsKmsSupportPrivate Qt6QuickDialogs2QuickImpl
Qt6FbSupportPrivate Qt6QuickDialogs2Utils
Qt6Gui Qt6QuickLayouts
Qt6GuiTools Qt6QuickParticlesPrivate
Qt6Help Qt6QuickShapesPrivate
Qt6HostInfo Qt6QuickTemplates2
Qt6InputSupportPrivate Qt6QuickTest
Qt6KmsSupportPrivate Qt6QuickTestUtilsPrivate
Qt6LabsAnimation Qt6QuickWidgets
Qt6LabsFolderListModel Qt6Sql
Qt6LabsQmlModels Qt6Svg
Qt6LabsSettings Qt6SvgWidgets
Qt6LabsSharedImage Qt6Test
Qt6LabsWavefrontMesh Qt6Tools
Qt6Linguist Qt6ToolsTools
Qt6LinguistTools Qt6UiPlugin
Qt6Network Qt6UiTools
Qt6OpenGL Qt6WaylandClient
Qt6OpenGLWidgets Qt6WaylandEglClientHwIntegrationPrivate
Qt6PacketProtocolPrivate Qt6WaylandScannerTools
Qt6PrintSupport Qt6Widgets
Qt6Qml Qt6WidgetsTools
Qt6QmlCompilerPrivate Qt6WlShellIntegrationPrivate
Qt6QmlCore Qt6XcbQpaPrivate
Qt6QmlDebugPrivate Qt6Xml
Qt6QmlDevToolsPrivate
这些都是 QT6 的components 其中 Qt6OpenGL 和 Qt6OpenGLWidgets 是与opengl 有关的
于是我们在CMakefilelist.txt 中可以这样添加opengl
1 | find_package(Qt${QT_VERSION_MAJOR} COMPONENTS Widgets OpenGL OpenGLWidgets REQUIRED) |
即可
如果要添加其他的库, 不妨先看看 /lib/cmake 文件夹下有什么
coc.nvim ccls C++补全
https://devbins.github.io/post/ccls/
clangd 补全
coc-settings.json
1 | { |
其中
“suggest.noselect”: false
自动选中预览窗口第一个
“suggest.noselect”: false
在CMakeLists.txt 设置 生成 coc.settings.json (位于build 目录下)
1 | set(CMAKE_EXPORT_COMPILE_COMMANDS ON) |
并在 coc.settings.json 中设置
“build/compile_commands.json”
根据 compile_commands.json 才能找到头文件。。。
在根目录下使用ccls 导致失败
Server languageserver.ccls failed to start: Error: invalid params of initialize: e
xpected array for /workspaceFolders
openMP 并行计算
安装
1 | sudo apt install libomp-dev |
cmake 报警告无法正确链接 openMP
手动添加链接 -fopenmp 报警告
warning: ignoring #pragma omp parallel [-Wunknown-pragmas]
正确的做法
1 | find_package(OpenMP REQUIRED) |
https://stackoverflow.com/questions/17633513/cmake-cannot-find-openmp
https://cliutils.gitlab.io/modern-cmake/chapters/packages/OpenMP.html
开启并行比不开启还要慢
先排查是否使用了clock函数
clock()有三个问题:
1)如果超过一个小时,将要导致溢出.
2)函数clock没有考虑CPU被子进程使用的情况.
3)也不能区分用户空间和内核空间.
应该使用double omp_get_wtime( );omp_get_wtime函数(单位 秒)可以返回从某个特殊点所经过的时间
https://blog.csdn.net/weixin_45873341/article/details/109225043
最后发现是我非常蠢的把 #pragma omp parallel 之后的 for 循环 写成了 #pragma omp parallel for 这样 parallel 了两遍
1 |
|
这样我的电脑上 8 核跑满 加速比 ~ 6.
安装docker ubuntu20.04
1 | sudo apt install docker.io |
解决docker 需要sudo 才能使用的问题(转载)
作者:AceCream佳
链接:https://www.jianshu.com/p/1354e0506753
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Q:首先说一下问题是怎么出现的?
A:Docker的守护线程绑定的是unix socket,而不是TCP端口,这个套接字默认属于root,其他用户可以通过sudo去访问这个套接字文件。所以docker服务进程都是以root账户运行。
解决的方式是创建docker用户组,把应用用户加入到docker用户组里面。只要docker组里的用户都可以直接执行docker命令。
可以先通过指令查看是否有用户组:1
cat /etc/group | grep docker
如果有就跳过第一步!
第一步:创建docker用户组
1 | sudo groupadd docker |
第二步:用户加入到用户组1
sudo usermod -aG docker 用户名
第三步:检查是否有效1
cat /etc/group
第四步:重启docker-daemon1
sudo systemctl restart docker
第五步:给docker.sock添加权限1
sudo chmod a+rw /var/run/docker.sock
作者:AceCream佳
链接:https://www.jianshu.com/p/1354e0506753
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
docker 构建C/C++ 环境镜像 并上传到 dockerhub
创建 ubuntu 容器
1.拉取ubuntu
1 | docker pull ubuntu |
Using default tag: latest
latest: Pulling from library/ubuntu
08c01a0ec47e: Pull complete
Digest: sha256:669e010b58baf5beb2836b253c1fd5768333f0d1dbcb834f7c07a4dc93f474be
Status: Downloaded newer image for ubuntu:latest
docker.io/library/ubuntu:latest
2.启动镜像 实例化一个容器 并命名为 cpp 映射端口 为 6789 挂载容器的 /root 目录到 ~/docker/root 主机名为elles
1 | docker run -it --name cpp -p 6789:22 -h elles -v ~/docker/root:/root ubuntu:latest |
需要注意的是 这样挂载后在root是存不住东西的貌似 。。。
docker run 的常见选项
| 选项 | 描述 |
|---|---|
| -i | 交互式 |
| -t | 分配一个模拟终端 |
| -d | 后台运行容器 |
| -e | 设置环境变量 |
| -p | 发布容器端口到主机 主机端口:容器端口 如 5022:22 |
| -P | 随机分配一个本机端口对应容器端口 |
| —name string | 指定容器名 |
| -h | 指定容器的主机名 |
| -ip | 指定容器IP 只能用于自定网络 |
| -network | 容器的网络模式 |
| -v | 绑定挂载一个卷 |
| -restart string | 容器退出时的重启策略 默认 no |
容器资源限制
| 选型 | 描述 |
|---|---|
| -m | 容器可以使用的最大内存 |
| -memory-swap | 允许交换到磁盘的内存量 |
| -memory-swappiness=<0-100> | 容器使用swap分区交换的百分比(0-100,默认为-1) |
| —oom-kill-disable | 禁止 OOM killer |
| —cpus | 可使用的cpu 数量 |
| —cpuset-cpus | 限制容器使用特定的cpu 核心 如 (0-3,0,1) |
| —cpu-shares | cpu共享(相对权重) |
ocker 容器资源限制
内存限制-m参数,允许容器最多使用500M内存和100M的swap,并禁用OOM killer
--memory="500m" --memory-swap="100m" --oom-kill-disable
cpu限额 ,允许容器最多使用一个的cpu
--cpus="1"
允许容器最多使用50%的cpu
-cpus=".5"
与宿主即共享数据
也就是通过 -v 挂载卷
容器安装 C/C++ 编译环境 配置 .bashrc
因为已经 是 root 用户了所以 不需要再加 sudo
1 | apt update |
在 容器的 root 文件夹下新建 .bashrc , .vimrc
1 | export CC=/usr/bin/gcc |
激活配置
1 | source .bashrc |
.vimrc
1 | set ts=4 |
新建文件 ~/Templates/CMakeLists.txt
1 | mkdir Templates |
CMakeLists.txt 内容
1 | cmake_minimum_required(VERSION 3.0) |
这样 配置就算完成了
如果想要新建一个C++ 项目
1 | cInit project_name |
项目结构为
1 | . |
想要运行程序 在 项目的根目录下运行
1 | run |
即可
vscode 链接 ssh 访问容器
1 | apt-get install openssh-server |
修改密码
1 | passwd |
修改配置文件
1 | vim /etc/ssh/sshd_config |
做如下改动
1 | #PermitRootLogin prohibit-password |
重启ssh
1 | /etc/init.d/ssh restart |
在本机查询容器的 信息
1 | docker container ls |
1 | CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES |
ip 为0.0.0.0 端口 6789
于是在vscode 中可以.ssh/config 中配置
1 | Host elles #这行是名字无所谓。。。下面的 HostName 和 Port 一定要填对 |
然后登录密码 就可以了
然后在vscode 中可以为 容器装 插件。。。
可能遇到的问题
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!Someone could be eavesdropping on you right now (man-in-the-middle attack)!It is also possible that the RSA host key has just been changed.The fingerprint for the RSA key sent by the remote host is36:68:a6:e6:43:34:6b:82:d7:f4:df:1f:c2:e7:37:cc.Please contact your system administrator.Add correct host key in /u/xlian008/.ssh/known_hosts to get rid of this message.Offending key in /u/xlian008/.ssh/known_hosts:2RSA host key for 135.1.35.130 has changed and you have requested strict checking.Host key verification failed.
这个只需
1 | vim .ssh/known_hosts |
删除对应的内容即可
将容器制作为镜像上传 dockerhub 并在别的环境上下载
1 | docker commit -a "author name" -m "cpp" 容器ID 镜像名字 |
1 | docker login |
给自己的镜像打上标签
1 | docker tag cpp:latest dockerhub_usrname/cpp:v1 |
此时
1 | docker images |
会显示
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
然后再运行
1 | docker push dockerhub_usrname/cpp:v1 |
即可把镜像推送到 dockerhub !
只需要在别的电脑上 pull 一下即可把环境下载!
1 | docker pull dockerhub_usrname/cpp:v1 |
安装eigen
1 | sudo apt-get install libeigen3-dev |
测试程序
1 |
|
安装openGL
1 | sudo apt-get install build-essential |
然后在 CMakeLists.txt 链接库即可 请不要随意更变参数书写顺序,否则可能不能编译1
target_link_libraries(${PROJECT_NAME} PUBLIC -lglut -lGLU -lGL -lX11 -lXext -lXi -lm )
转载文章
https://zhuanlan.zhihu.com/p/373743580
OpenGL 函数库相关的 API 有核心库(gl),实用库(glu),辅助库(aux)、实用工具库(glut),窗口库(glx、agl、wgl)和扩展函数库等。gl 是核心,glu 是对 gl 的部分封装。glx、agl、wgl 是针对不同窗口系统的函数。glut 是为跨平台的 OpenGL 程序的工具包,比aux 功能强大(aux 很大程度上已经被 glut 库取代)。扩展函数库是硬件厂商为实现硬件更新利用 OpenGL 的扩展机制开发的函数。
窗口管理
窗口操作在每个系统上都是不一样的,OpenGL 有目的地将这些操作抽象(Abstract)出去。这意味着我们不得不自己处理创建窗口,定义 OpenGL 上下文以及处理用户输入。幸运的是,有一些库已经提供了我们所需的功能。这些库节省了我们书写操作系统相关代码的时间,提供给我们一个窗口和上下文用来渲染。
glut
OpenGL 工具库(OpenGL Utility Toolkit),所有 glut 的库函数均以 glut 开头,但是版本太老了,理应被时代淘汰,不推荐使用。gult 最后版本 v3.7beta 的历史可追溯至 1998 年 8月,且该项目已经被废弃。它的许可证禁止任何人发布修改后的库代码。
freeglut
gult 对应的开源实现,完全兼容 glut,是 glut 的代替品,开源,功能齐全。目前来看,freeglut3.0(2015年3月7日)版本比其它版本稳定,可以使用。该项目几乎可以 100% 的替代原来的 glut,只有少数差别(如,the abandonment of SGI-specific features,按钮盒子和动态视频分辨率)和其他一小部分程序 bug。
glfw
glfw 无愧于其号称的 lightweight 的 OpenGL 框架,的确是除了跨平台必要做的事情都没有做,所以一个头文件,很少量的 API,就完成了任务。glfw 的开发目的是用于替代 glut 的,从代码和功能上来看,我想它已经完全的完成了任务。它是一个轻量级的,开源的,跨平台的library。支持 OpenGL 及 OpenGL ES,用来管理窗口,读取输入,处理事件等。
函数加载
OpenGL 只是一个标准/规范,具体的实现是驱动开发商针对特定显卡实现的。由于 OpenGL 驱动版本众多,它大多数函数的位置都无法在编译时确定下来,需要在运行时查询。所以任务就落在了开发者身上,开发者需要在运行时获取函数地址并将其保存在一个函数指针中供以后使用。这个过程非常复杂,而且很繁琐,需要对每个可能使用的函数都要重复这个过程。幸运的是,有些库能简化此过程。
glew
glut 或者 freegult 主要是 OpenGL 1.0 的基本函数功能,glew 是使用 OpenGL 2.0 之后的一个工具函数。
不同的显卡公司会发布一些只有自家显卡才支持的扩展函数,要想用这数涵数,不得不去寻找最新的 glext.h,有了 glew 扩展库,就再也不用为找不到函数的接口而烦恼,因为 glew 能自动识别你的平台所支持的全部 OpenGL 高级扩展函数。也就是说,只要包含一个 glew.h 头文件,你就能使用 gl,glu,glext,wgl,glx 的全部函数。
glew 支持目前流行的各种操作系统,但有一个缺陷是它并没有提供一种方式可以屏蔽 OpenGL 旧函数的调用,尽管可以使用 Core profile 的方式,但是代码中仍然存在 glVetex、glBegin 这样固定管线 OpenGL 的函数调用(虽然它们在 Core Profile 模式下没有任何作用),看起来不那么统一。要做到这一点可以使用下面的 glad。
glad
glad 是继 gl3w,glew 之后,当前最新的用来访问 OpenGL 规范接口的第三方库。简单说glad 是 glew 的升级版。
glad 是一个开源的库,它的配置与大多数的开源库有些许的不同,glad 使用了一个在线服务。在这里能够指定 glad 需要定义的 OpenGL 版本,并且根据这个版本加载所有相关的OpenGL 函数。这样做让 glad.h 中仅仅只包含我们想要的头文件,例如在设置 3.3 + Core Profile 版本之后,可以严格控制头文件中只有这些内容,所以凡是代码中有 OpenGL 旧函数的调用都会在编译的时候给出错误提示。
glfw + glad + VS 进行开发
glfw 下载
glfw 可以从官方网站的下载页上获取。glfw 有预编译的二进制版本和相应的头文件,但是为了完整性最好从编译源代码开始。下载源代码包之后,将其解压并打开,最后只需要 编译生成的库 和 include 文件夹。
从源代码编译库可以保证生成的库是兼容你的操作系统和 CPU 的,而预编译的二进制文件可能会出现兼容问题(甚至有时候没提供支持你系统的文件)。提供源代码所产生的一个问题在于不是每个人都用相同的 IDE 开发程序,因而提供的工程/解决方案文件可能和一些人的 IDE不兼容。所以人们只能从 .c/.cpp 和 .h/.hpp 文件来自己建立工程/解决方案,这是一项枯燥的工作。但因此也诞生了一个叫做 CMake 的工具。
CMake 生成工程文件
CMake 是一个工程文件生成工具。用户可以使用预定义好的 CMake 脚本,根据自己的选择(像是 Visual Studio,Code::Blocks,,Eclipse)生成不同 IDE 的工程文件。首先,从这里下载安装 CMake。
安装成功后启动,CMake 需要一个源代码目录和一个存放编译结果的目标文件目录。源代码目录是 glfw 的源代码的根目录(解压的目录),然后在根目录下新建一个 build 文件夹,选中作为目标目录。设置之后,点击 Configure(设置)按钮,根据使用的 VS 版本选择工程的生成器,我选择的是 Visual Studio 16 2019选项(因为 Visual Studio 2019 的内部版本号是16)。CMake 会显示可选的编译选项用来配置最终生成的库,这里使用默认设置,点击 finish 按钮。之后再次点击 Configure(设置)按钮保存设置。保存之后,点击 Generate(生成)按钮,生成的工程文件会在 build 文件夹中。
VS 编译
在 build 文件夹里找到 GLFW.sln 文件,用 Visual Studio 打开。因为 CMake 已经配置好了项目,所以直接点击 Build Solution(生成解决方案)按钮,然后编译的库 glfw3.lib(注意这里用的是第3版)就会出现在 src/Debug 文件夹内。
让 IDE 知道库和头文件的位置
有两种方案:
(不推荐)找到 IDE 或者编译器的 /lib 和 /include 文件夹,添加 glfw 的 include 文件夹里的文件到 IDE 的 /include 文件夹里去。用类似的方法,将 glfw3.lib 添加到 /lib 文件夹里去。虽然这样能工作,但这不是推荐的方式,因为这样会让你很难去管理库和 include 文件,而且重新安装 IDE 或编译器可能会导致这些文件丢失。
(推荐)建立一个新的目录包含所有的第三方库文件和头文件,并且在 IDE 或编译器中指定这些文件夹。我个人会使用一个单独的文件夹,里面包含 lib 和 include 文件夹,在这里存放 OpenGL 工程用到的所有第三方库和头文件。这样我的所有第三方库都在同一个位置(并且可以共享至多台电脑)。然而这要求你每次新建一个工程时都需要告诉 IDE/编译器在哪能找到这些目录。
用 VS 创建一个新的项目,选对平台(x86 / x64),首先进入Project Properties(属性,在解决方案窗口里右键项目),然后选择 VC++ Directories(VC++ 目录)。在右边的 Include Directories(包含目录)和 Library Directoried(库目录)分别把之前的 include 和 lib 文件夹目录加进去,现在VS可以找到所需的所有文件了。
要链接一个库必须告诉链接器它的文件名。库名字是 glfw3.lib,把它加到 Linker(链接器)选项卡里的 Input(输入)选项卡的 Additional Dependencies(附加依赖项)。这样 glfw 在编译的时候就会被链接进来了。除了 glfw 之外,还需要添加一个链接条目链接到 OpenGL 的库,但是这个库可能因为系统的不同而有一些差别,Windows平台下 opengl32.lib 已经包含在 Microsoft SDK 里了,它在 Visual Studio 安装的时候就默认安装了,因此只需将 opengl32.lib添加进连接器设置里就行了。
配置 glad
打开 glad 的在线服务,将语言(Language)设置为 C/C++,在API选项中,选择 3.3 以上的 OpenGL(gl) 版本(这里使用3.3版本,但更新的版本也能正常工作)。之后将模式(Profile)设置为 Core,并且保证生成加载器(Generate a loader)的选项是选中的。现在可以先(暂时)忽略拓展(Extensions)中的内容。都选择完之后,点击生成(Generate)按钮来生成库文件。
glad 现在提供给了一个 zip 压缩文件,包含两个头文件目录,和一个 glad.c 文件。将两个头文件目录(glad 和 KHR)复制到之前 include 文件夹中,并添加 glad.c 文件到你的工程中(文件放 src,同时 VS 中也要添加以下)。
经过前面的这些步骤之后,新建一个 .cpp 文件:
1 |
|
点击编译按钮不提示任何的错误则配置完成。
glad glfw 安装参考:
1 | sudo apt-get install libglfw3-dev # 安装glfw3 |
根据显示的 版本 在网站 https://glad.dav1d.de/ 生成 glad 文件 并复制到工程中即可 cmake 中配置文件目录 不多赘述
LeetCode 插件无法登陆
Leetcode:Endpoint
设置为 leetcode-cn
用bash 从参数列表 循环读取参数 传递给 c 程序
例如 main 是可执行程序,参数列表文件为 args.txt 每行为一组参数1
2
3argv[1] argv[2] ...
argv[1] argv[2] ...1
cat args.txt | while read line;do main $line ;done
fopen
‘r’ 只读方式打开,将文件指针指向文件头,如果文件不存在,则File返回空。
‘r+’ 读写方式打开,将文件指针指向文件头,如果文件不存在,则File返回空。
‘w’ 写入方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建之。
‘w+’ 读写方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建之。
‘a’ 写入方式打开,将文件指针指向文件末尾。如果文件不存在则尝试创建之。
‘a+’ 读写方式打开,将文件指针指向文件末尾。如果文件不存在则尝试创建之。
‘x’ 创建并以写入方式打开,将文件指针指向文件头。如果文件已存在,则 fopen() 调用失败并返回 FALSE。
‘x’ 创建并以写入方式打开,将文件指针指向文件头。如果文件已存在,则 fopen() 调用失败并返回 FALSE。
‘b’ 使用字符b作为文件类型的判断,是否是binary文件。
值得注意的是,要想清空一个文件,只需要用 w 模式打开再关闭即可1
2
3
4
5
6
7FILE* fp0=fopen(outputdir,"w");
fclose(fp0);
FILE* fp=fopen(outputdir,"a");
/*code*/
fclose(fp);
vscode C/C++ 相关设置
vs code调试-监视 查看全部数组元素
(type()[number])begin
type,类型
number,查看数量
begin,起始地址指针
设置自动换行
设置里的Editor:Word Wrap 打开即可
无法自动补全结构体 的成员 因为头文件目录不正确
经过n多设置还是没有用
最后发现,是因为在主函数里面定义函数,就识别不出来了。。。
禁用问题提示
设置中搜索 C_Cpp.errorSquiggles 禁用即可
https://www.php.cn/tool/vscode/434548.html#:~:text=%EE%80%80vscode%E5%85%B3,disable%E3%80%82
VS Code修改系统界面和编辑面板字体大小
https://blog.csdn.net/chenbetter1996/article/details/85166528
vscode 断点调试
vscode调试(debug)的几个按键功能详解
F5-继续:直接跳到下一个断点
单步跳过:运行到当前文件夹的下一行,跳过当前语句,调用其他文件夹的所有语句。比如a = func_b©,如果func_b是其他文件夹定义的复杂函数,直接跳过;
单步调试:运行到自己写的文件下一行语句,比如a = func_b©,如果func_b是其他文件定义的复杂函数,则进入其他文件,运行下一步;
单步跳出:当debug陷入某个循环时,直接跳过当前循环。
重启,重新debug
gdb 调试

scanf 读取数据
1 | char hello[]="HelloWorld"; |
似乎空格和 字符串冲突。。。所以最好直接写数据 不写入字符串。。。
多文件使用全局变量
1.在头文件中声明,记得加extern 关键字
1 | extern const int a; |
2.在源文件中定义1
const int a = 1;
CMakeLists.txt 模板更新 原来的可以扔了。。。
1 | cmake_minimum_required(VERSION 3.0) |
scanf getchar 混合多次使用要当心
从 stdin 输入必须按回车键, 回车键会被储存在缓冲区内,下次使用getchar()就会读取回车键,于是不能正确执行。
可以多加一个 getchar()或使用 fflush(stdin) 清空缓冲区。
https://blog.csdn.net/suifengmoon123/article/details/40511961
https://jingyan.baidu.com/article/fea4511a715f3bf7bb9125d7.html
CMakeLists.txt 模板
项目文件夹结构1
2
3
4
5
6
7
8.
├── bin
├── build
├── CMakeLists.txt
├── include
└── src
└── main.c
CMakeLists.txt 模板1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30cmake_minimum_required(VERSION 3.0)
project(main)
#设置编译器路径gcc,g++ 不要在本文件中设置!
#需要在.bashrc 中声明
#export CC=/usr/bin/gcc
#export CXX=/usr/bin/g++
#查找 src 中的源文件
aux_source_directory(src SC_FILES)
# 指定生成目标
add_executable(${PROJECT_NAME} ${SC_FILES})
# 规定.h头文件路径, 这里的 include 是你项目文件夹下的 include 子文件夹, YOUR_INCLUDE_PATH 则是不在项目文件夹下的头文件路径
include_directories(include YOUR_INCLUDE_PATH)
# 规定.so/.a库文件路径 设置链接参数,如libm.so 就需要 -lm
link_directories(YOUR_LIB_PATH )
target_link_libraries(${PROJECT_NAME} -lYOUR_LIB)
#设置可执行文件的生成路径,编译在 build 子文件夹,可执行文件设置为 上级目录 ,也就是项目根目录的 bin 子目录中
SET(EXECUTABLE_OUTPUT_PATH ../bin)
set(CMAKE_INSTALL_PREFIX "../bin/")
install(TARGETS ${PROJECT_NAME} RUNTIME DESTINATION ${CMAKE_INSTALL_PREFIX})
编译后目录
1 | . |
python 导入 C 语言 并速度对比
源文件
1 |
|
生成共享库
1 | gcc -fPIC -shared test.c -o libtest.so |
速度比较
1 | from ctypes import * |
1 | #numpy 创建时间记录在内 |
100000000.0
0.13338828086853027
1 | #numpy 创建时间不记录在内 |
0.09000158309936523
100000000.0
0.04085993766784668
1 | #C语言 |
100000000
0.14220285415649414
1 | #无numba加速 |
100000000
3.4196369647979736
1 | #numba加速 |
100000000
0.26204824447631836
1 | #numba加速 第二次运行 比第一次会快很多 |
100000000
0.08586692810058594
增加10倍数据量
1 | from ctypes import * |
1 | #numpy 创建时间记录在内 |
1000000000.0
62.575740814208984
1 | #numpy 创建时间不记录在内 |
36.15015482902527
1000000000.0
5.647027015686035
1 | #C语言 |
1000000000
1.449312448501587
1 | #无numba加速 |
1000000000
34.22473168373108
1 | #numba加速 |
1000000000
1.5348374843597412
数据量变大时,numpy 速度出现明显下降,并不与数据量大小成正比
c语言和python numba加速 运行时间与数据量成正比。综合来看 c语言在数据量较小时 与numpy比 并没有明显优势,但是一旦数据量增大,其优势是巨大的,numba 加速第一次运算时 略慢于 c 但是二次运行后 比c快很多。
详细说明char*,const char*,char **,const char **,char * const *,以及他们对应的赋值关系
概念解释
简单说一下const 与指针.
char *p 与 const char *p
char *p ,这个很简单,一个指向char a 的指针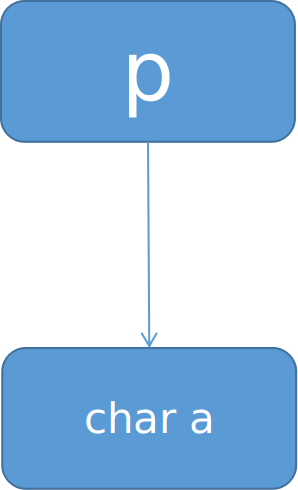
const char *p ,这个也简单,一个指向const char a 的指针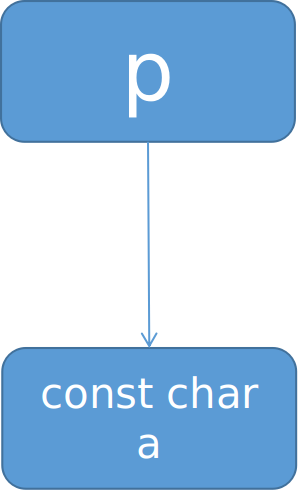
char **p,const char **p 与 char *const *p
char **p 可以看做 *(*p),p是一个指针,指向另一个指针*p,指针*p则指向char a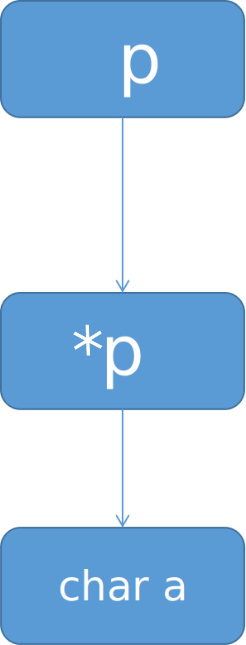
const char **p与 char **p 类似,只不过最终指向一个 const char a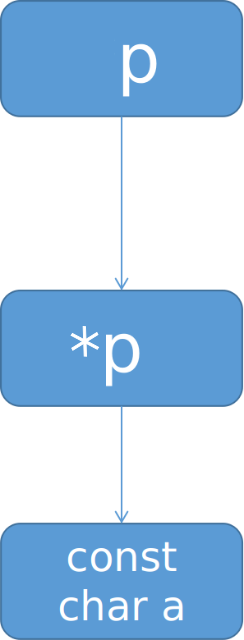
char *const *p , p 指向一个const 指针 const p,也就是指针 p 无法被改写,无法指向新的内存区域,强行改写就会报错。 *p指向一个char a。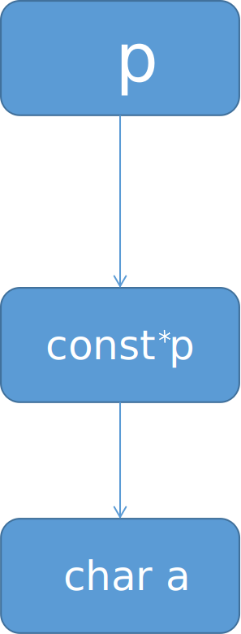
赋值问题
char *p 赋值给 const char *p (只读指针)
指针赋值的意思应该是被赋值的指针改变指向,指向赋值指针所指内存,并且要保留被赋值指针的类型.
如图,讲char *p 赋值给 const char *q, 意味着q 要将指针由 const char b 指向 char a , 由于q本来是 const char * 类型的,指向别的内存空间不会导致自身的类型(只读指针)发生变化,不会导致什么问题,唯一的缺点是不能够使用指针 q 来改写 char a 的数据(p 则可以)。
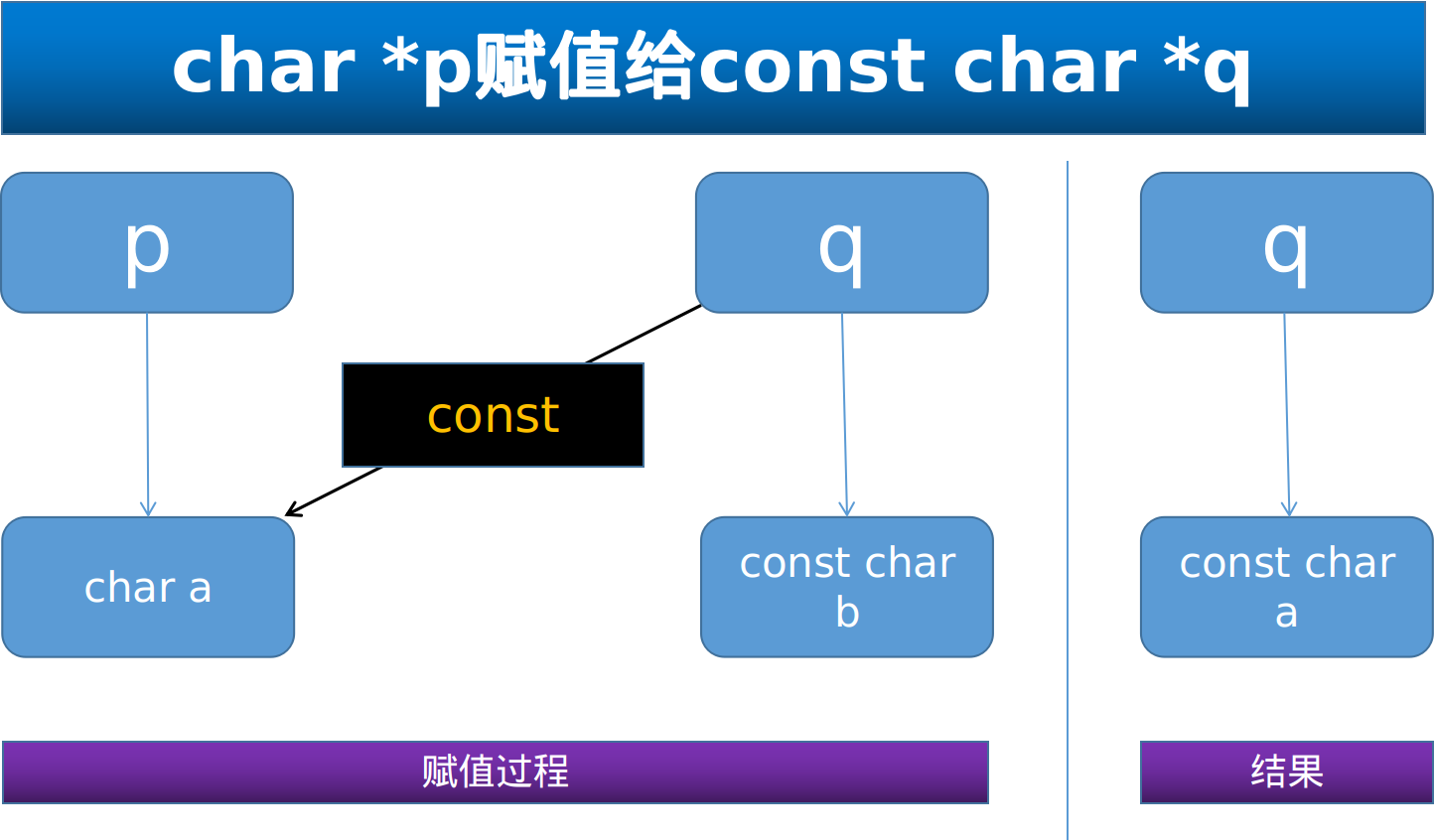
const char *p 赋值给 char *p
看看反过来是什么情况 :
可以看到, const char a 被 q抹去了const 变为了一个 char型,但是原本a 定义为const char 就是不希望其中的值被改写,但是现在可以通过q来改写a,这就会导致问题,故这种赋值是不被允许的.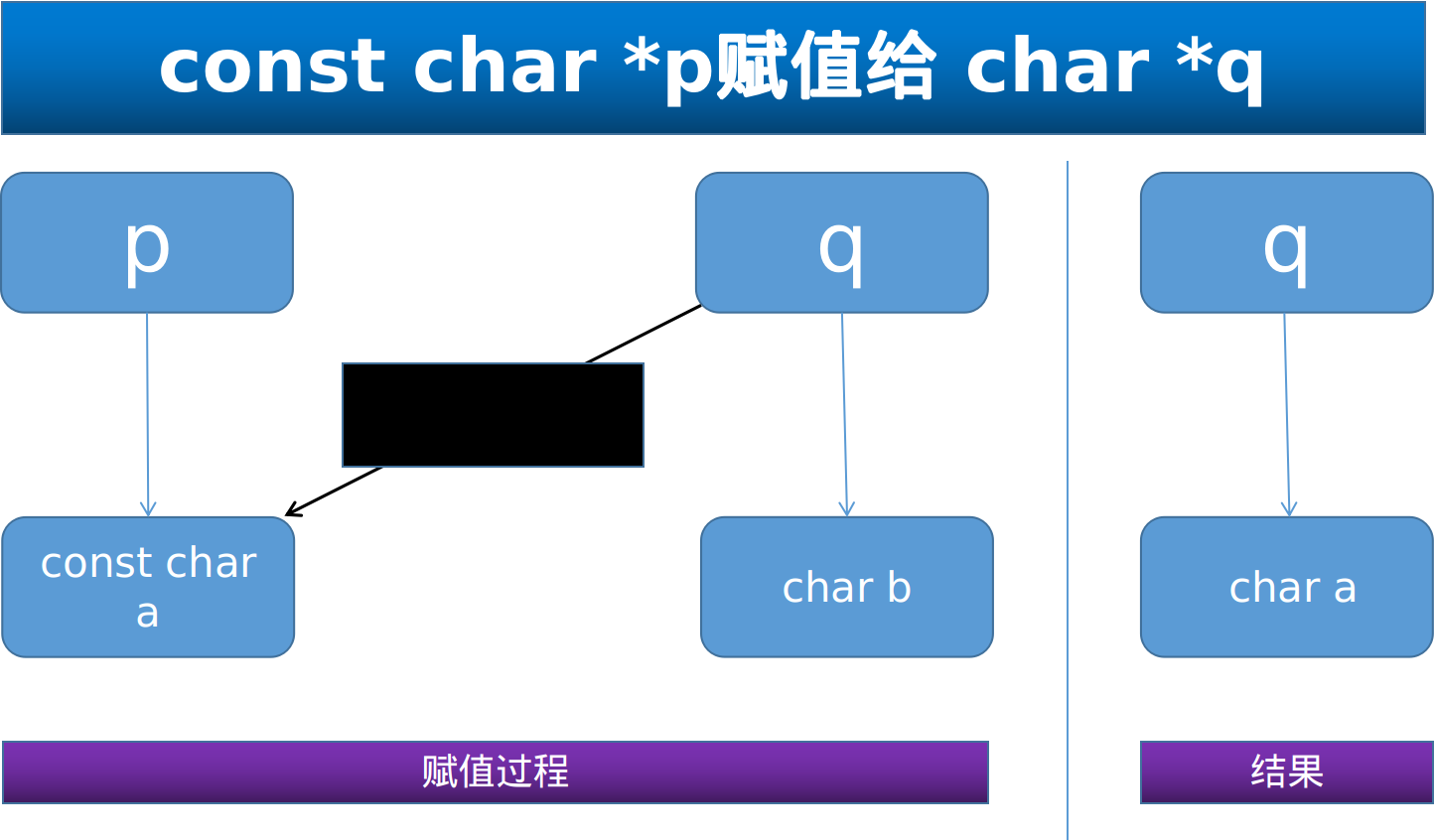
char** p 赋值给const char **p
这种赋值其实只发生在第一层,即改变指针的指针的指向(是不是太绕了…)
总之,最终的结果是,复制完毕后,被赋值的指针q竟然由const char **类型 变为了char **类型,这样也太奇怪了吧?
因此这种赋值也是不允许的.
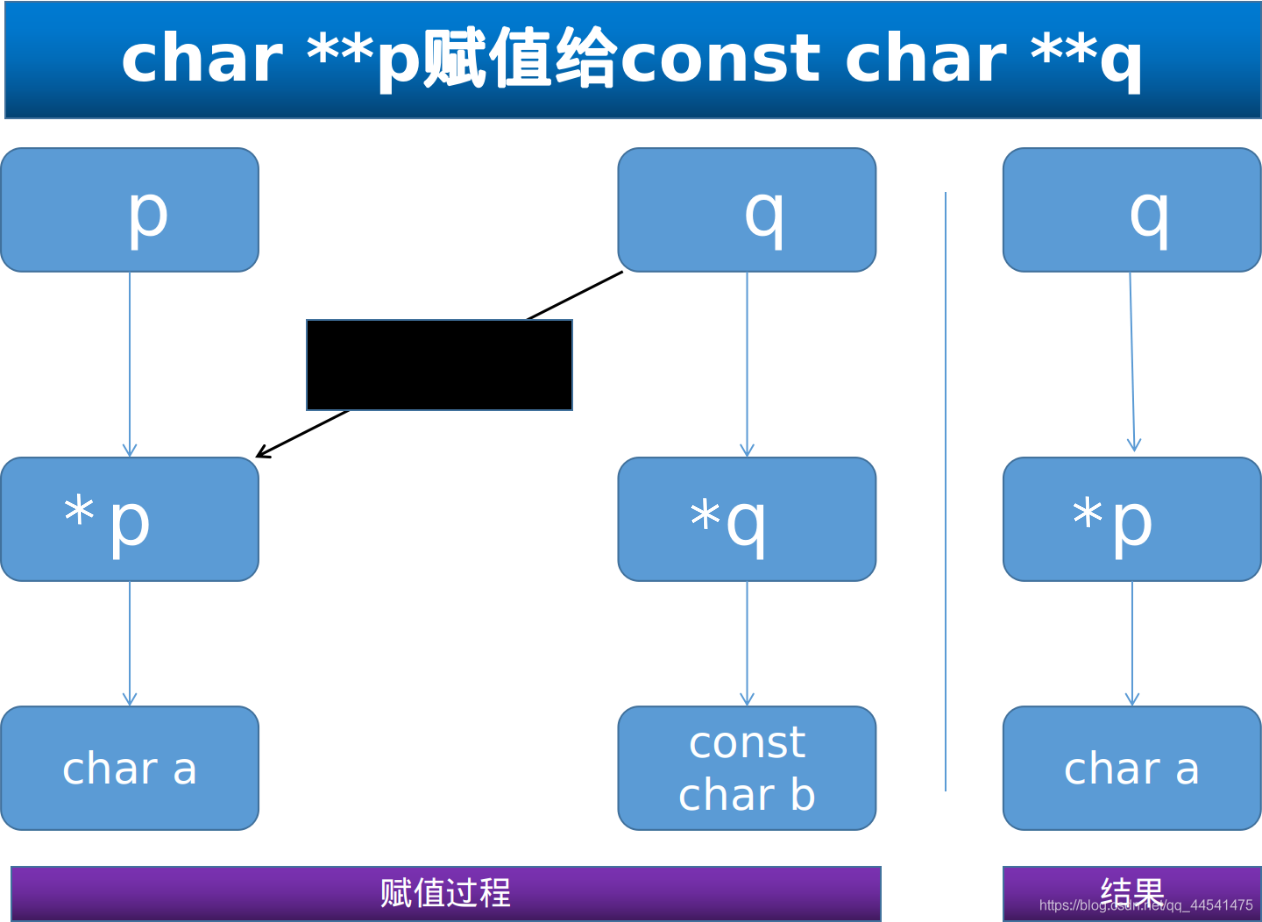
char** p 赋值给char *const *q
赋值完成后,被赋值指针类型没改变,而且也没有const 型被改写,so far so good,
因此这种赋值是可以的,但要是 const char **p赋值给char *const *q,则会导致被赋值指针类型改变,就会出问题了.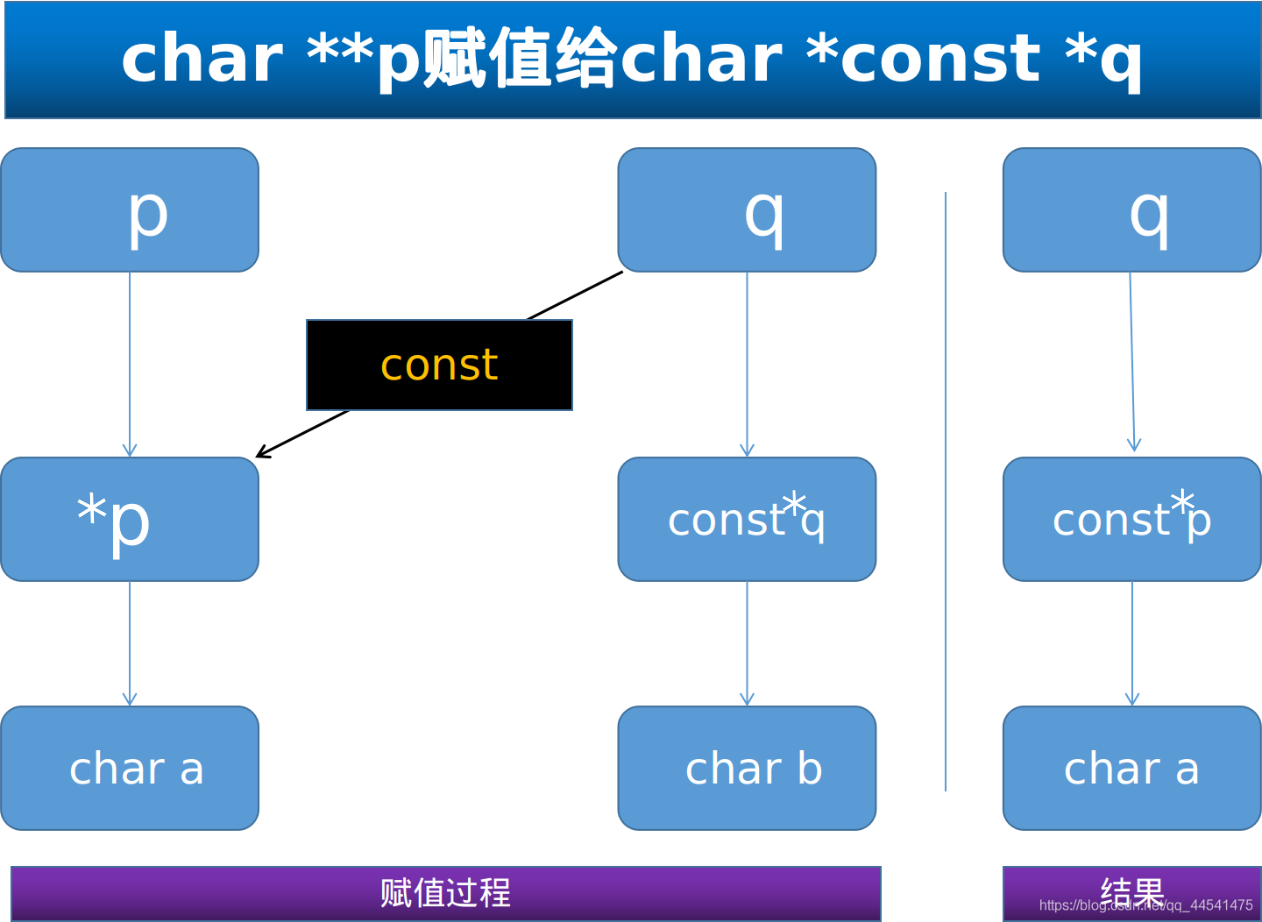
其他
其实都差不多…,只要明白赋值后哪些地方改变了,这些改变是否是被禁止的就可以了…
小结
刚学c语言指针,可能理解的不是很正确,如果有错,请指出…
目前我理解的被禁止的赋值:
1.赋值会导致指针可以改写 const 类型数据的。
2.赋值会导致被赋值的指针类型发生改变的
c++ 分开头文件
声明和实现为什么要分开写
现在开始写项目了,你会发现我们一般都要写一个cpp,对应的还得有一个h文件,那么为什么在C++中我们要这么做?
.h就是声明,.cpp就是实现,而所谓分离式实现就是指“声明”和“定义”分别保存在不同的文件中,声明保存在.h文件、定义保存在.cpp文件中。
那么将声明和定义分离有什么意义吗?
首先从非分离式(声明的同时给出定义)看,其内容一般保存在.h文件中,以供多个源文件引用。
但是将定义放在头文件,那么当多个源文件使用#include命令包含此类的头文件便会在链接阶段出现“multiple definition”链接错误!
那么想让多个文件使用此头文件,又不引发链接的“multiple definition”错误该怎么办呢?
分离式的实现便可以解决这个问题。因为.h文件中只包含声明,即使被多个源文件引用也不会导致“multiple definition”链接错误。
所以分离式实现增强了命名空间的实用性。
《Linux C一站式编程》
Linux C编程一站式学习 — PDF版本,共37章;
Linux C编程一站式学习 — 在线版,来自灰狐;
Linux C编程一站式学习 — 在线版,来自亚嵌教育;
Linux C一站式学习答案 — 来自 @胡永浩,托管在gitbook上;
Linux C一站式编程答案 — web版,可以对照查看,部分答案可能有问题;
可执行文件和目标文件的区别
可执行文件也是一种目标文件。UNIX环境下主要有三种类型的目标文件:
- 可重定位文件 .o 其中包含有适合于其它目标文件链接来创建一个可执行的或者共享的目标文件的代码和数据。
- 共享的目标文件 .a/.so 静态链接库和动态链接库,在生成可执行程序和其他共享代码库的时候,它们的链接方式不同。
- 可执行文件 它包含了一个可以被操作系统创建一个进程来执行之的文件。汇编程序生成的实际上是第一种 类型的目标文件。
c语言的 Makefile 文件
让我们来看看如何编译多个c语言文件。
原料: main.c, helloword.c, helloword.h
1 |
|
1 |
|
1 |
|
将这三个文件放于一个文件夹中,并编辑一个Makefile文件,文件内容为
1 | CC = gcc |
Makefile 文件可以自动建立文件之间的依赖关系,并自动编译,链接,最终得到名字为 main 的可执行文件。
需要注意的主要是
1.
CFLAGS 标签中你可以用 -IYOUR_HEADFILE_DIR 告知编译器你的头文件的位置(如果你的头文件放在了某些奇奇怪怪的位置)
2.
LIBS 标签里你可以用 -LYOUR_LIB_DIR 指定你的静态库的位置, 并且需要使用 -lYOUR_LIB_NAME 来指定你的静态库名称.
具体细节就不解释了,有兴趣的可以参考以下的博客
https://www.cnblogs.com/lidabo/p/4928942.html
然后运行1
2make
./main
当然,如果你还要连接位于YOUR_SHARE_LIB_DIR 的动态库, 那么只需要在 .bashrc 文件中配置一下路径:1
export LD_LIBRARY_PATH=YOUR_SHARE_LIB_DIR:$LD_LIBRARY_PATH
最后,清理编译文件
1 | make clean |
使用多个c语言文件分开编译是开发大型程序的第一步!




